
If you’ve been in the tech space for a while or you’ve just been introduced to it, chances are that you’ve likely come across tweets or LinkedIn posts similar to the one below:
“A CS degree is no longer needed in [2026].”
It is our solemn duty as lovers and educators of tech to be absolutely clear about misleading statements like these. Are traditional CS degrees necessary for a burgeoning career in tech? No, absolutely not.
The writer of this article does not possess a CS degree, and while her career may not be described as “burgeoning”, it has consisted of an impossible number of nights wrestling with data structures, algorithms, backend logic twists, and she’s doing fine. You can definitely have a thriving career as a backend developer without a CS degree.
This naturally leads to the second question: “Do you need to understand foundational concepts taught in CS degrees for a tech career?” This one can get a bit tricky. Some developers today swear by the “fact” that the foundational concepts are overkill, but that may only work if you keep writing the same CRUD API endpoints you learnt from a Medium article and have little to no idea what your code is actually doing.
If you want to be the backend developer that other backend developers look for and command bytes and logic to dance to your tune, then yes, the foundational concepts are quite important. You may realize sooner or later that BIG O Notation and parallel computing are not only relevant for tech interviews but have real implications for systems you build.
However, here is a third question for you: While traditional CS degrees and the curriculum are awesome for making great devs, what role do they play in modern backend systems, and more specifically, what role do they play in modern AI backend systems? This one will take some digging, and that’s where we’ll be heading next.
Moving from Deterministic to Probabilistic Systems
There is a certain “culture shock” that welcomes developers who have been quite steeped in the culture of traditional CS degrees and backend engineering to the field of AI backend engineering. That shock is the level of indeterminism their logic is forced to contend with. Unfortunately, AI systems don’t take in X, add Y, and produce a neat, predictable Z.
On the other hand, they may take in X, subtract Y instead, and do a headstand with Z. In essence, AI systems are largely probabilistic, which makes for a different way of working. You provide an input, and the system returns the most statistically likely output. This single shift breaks a lot of traditional backend design patterns and forces you to adopt a different engineering toolkit.
AI backend engineering is not just a buzzword; it’s a deeply technical field that requires the same rigorousness you’d find in traditional backend engineering. As we have emphasized from the start of the article, having a strong foundational CS background is important, but in order to succeed in the field, certain concepts require your focus. These are examined below.
Retrieval-Augmented Generation (RAG)
The concept of RAG deals with pulling relevant information from data and passing that data to a Large Language Model (LLM) as context. It concerns obtaining information from external sources, not limited to training data. This would force you to master the concept of vector embeddings (turning text into high-dimensional numerical arrays) and vector databases such as Pinecone, Milvus, or Weaviate.
Standard databases, when dealing with indexing, tend to match exact words, but vector databases perform what’s called a semantic search. This is rather about finding similar-meaning words, not exact matches. This is a concept that would be hard to explicitly trace to a traditional CS curriculum.
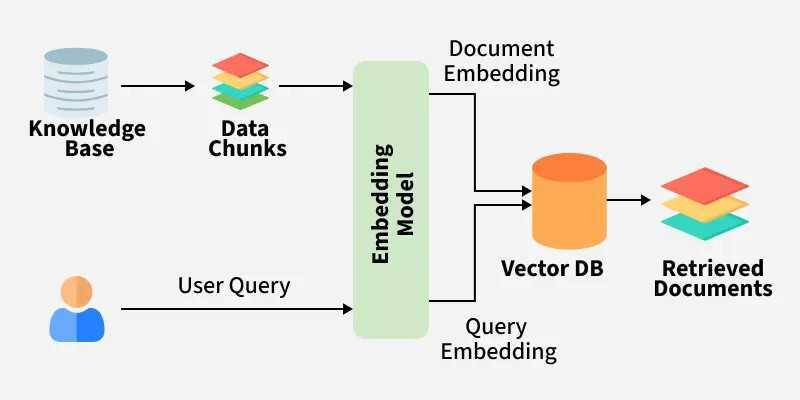 How RAG works (obtained from geeksforgeeks.org)
How RAG works (obtained from geeksforgeeks.org)
Probabilistic Observability
As stated previously, CS degrees place heavy emphasis on determinism. We know to input something and get something out. We also usually have some idea of what to expect for our output based on our input. This differs from what we find in AI systems that are more indeterministic.
This means that as an AI backend engineer, you have to track something known as prompt drift, which checks if your AI model’s quality degrades over time. You may also check for hallucination rates, which, as you may guess from the name, have something to do with the infamous AI “hallucination” which you can try to limit so your AI model does not confidently announce Plato was a woman or Japan is in Africa.
Idempotency in AI Agent Workflows
It is not enough that your AI system can send an email or add numbers. You usually have to ensure that if the AI retries again, they do not send 30 emails to a user. CS degrees may show you that the show ends with code execution. In AI backend systems, you design certain guardrails; logic that can intercept an AI’s output to ensure it does not accidentally delete an important database or reveal sensitive information.
This explains why AI backend engineers must design rigid, deterministic guardrails around these non-deterministic core systems. This involves runtime validation and output sanitization.
The above are only a few concepts to dig into when considering a career in AI backend engineering. A few others are token-aware resource management, sanitizing, and validating AI output.
At a Glance: Traditional vs AI Backend Engineering
Below is a table summarizing some differences between traditional backend engineering directly based on CS approaches and AI backend approaches:
Concept | Traditional CS/ Backend Approach | Modern AI Backend Approach |
Data Storage | Relational/NoSQL (Structured tables, exact indexing, ACID compliance) | Vector Databases (High-dimensional embedding arrays, semantic similarity search) |
System Behavior | Deterministic: Code follows explicit, predictable rules | Probabilistic: System relies on statistical weights and likelihoods |
Monitoring | Latency, throughput, CPU/Memory utilization, error rates | Token consumption, semantic drift, cost tracking, evaluation metrics |
Error Handling | Stack traces, explicit exception catching, and status codes | Guardrails, output parsing/validation, hallucination containment |
While these AI backend concepts may seem far removed from what you’d find in traditional CS degree courses, know that a lot of these are abstractions based on the foundational concepts themselves. For instance, to optimize a vector search, you still need to understand memory optimization; to scale an agent workflow, you still need to understand concurrency.
Conclusion
Traditional CS degrees are important for understanding CS foundations, which would help you to understand backend systems. However, they tend to be quite limiting when considered alone.
Modern backend systems, particularly AI backend systems, introduce interesting deviations and additions that show that the traditional curriculum is clearly not enough even though it's relevant. If you’re on your way to a career in AI backend engineering, or you would like to be a better engineer in the field, you can fill up the gaps left behind by traditional CS degrees with courses and bootcamps just like those organized by the Mastering Backend team.


